Using Policyfiles: YoloVer as a Workflow
WARNING: This guide is a work in progress. Check back often for new updates.
An example repository for this workflow is available on GitHub.
These slides are also available as a PDF: with notes or without notes.
This version compiled on 2016-07-11 13:28:57 -0500
|
For those of little patience, let’s begin with a quick overview of how policies work. |
|
|
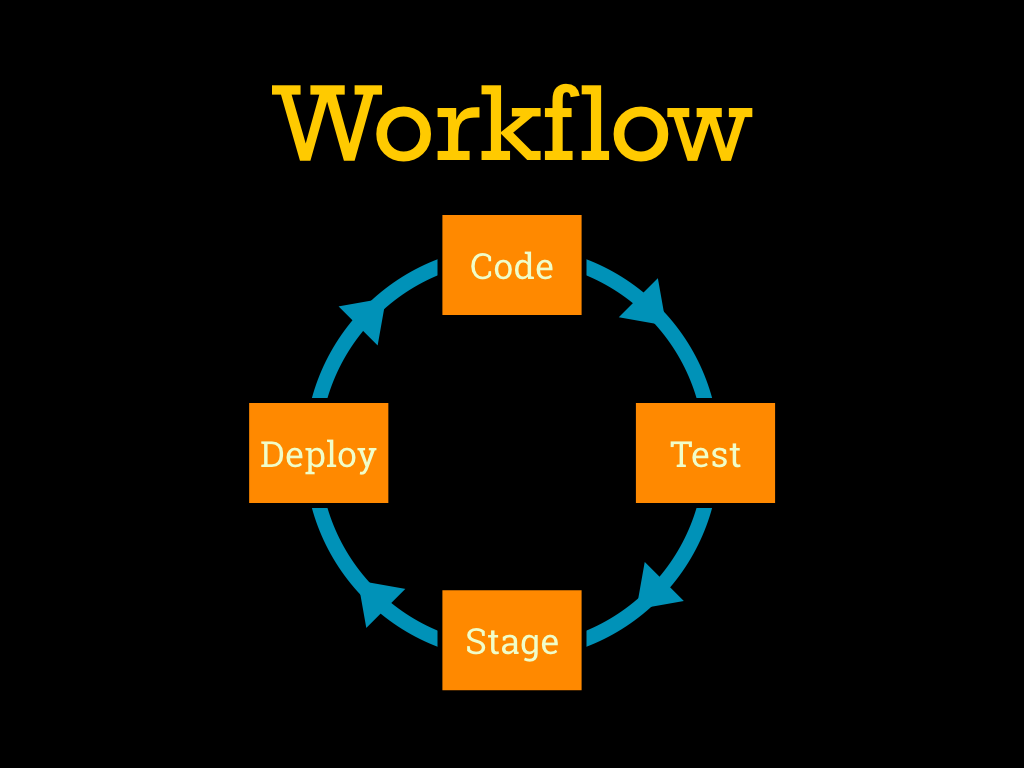
Any Chef workflow is going to have to hit four major points: writing the code, testing the code locally, managing some kind of staging or pre-production environment, and rolling things out to production. |
|
|
A few words you might not have seen before. The /usr/bin/chef command is a new command line tool that comes with ChefDK, kind of like knife but handles higher-level operations including working with policies. Policyfile, or Policyfile.rb, is a Ruby code file containing the description of a policy. Each node is attached to a single policy name and a single policy group, the policy name is like the role of the node and the group is like its environment. A compiled policy, or Policyfile.lock, is a snapshot of a completely resolved policy like Gemfile.lock or Berksfile.lock. |
|
|
A compiled policy on-disk is a JSON document with all the information from the Ruby source code as well as the specific cookbook versions that are going to be used with the policy and where they come from. |
|
|
The two main commands to get started with policies are “chef install” and “chef push”. install works like “berks install”, compiling the policy to a single snapshot and downloading all needed cookbooks to ~/.chefdk. push replaces commands like “berks upload” and “knife cookbook upload” to send the compiled policy and all the cookbooks it is using up to the Chef Server. |
|
|
With that short version out of the way, let’s look at a long version of what goes in a Policyfile and how to use them. |
|
|
The three main directives: |
|
|
|
|
|
In addition to setting the primary run list, we can also set addition named run lists via |
|
|
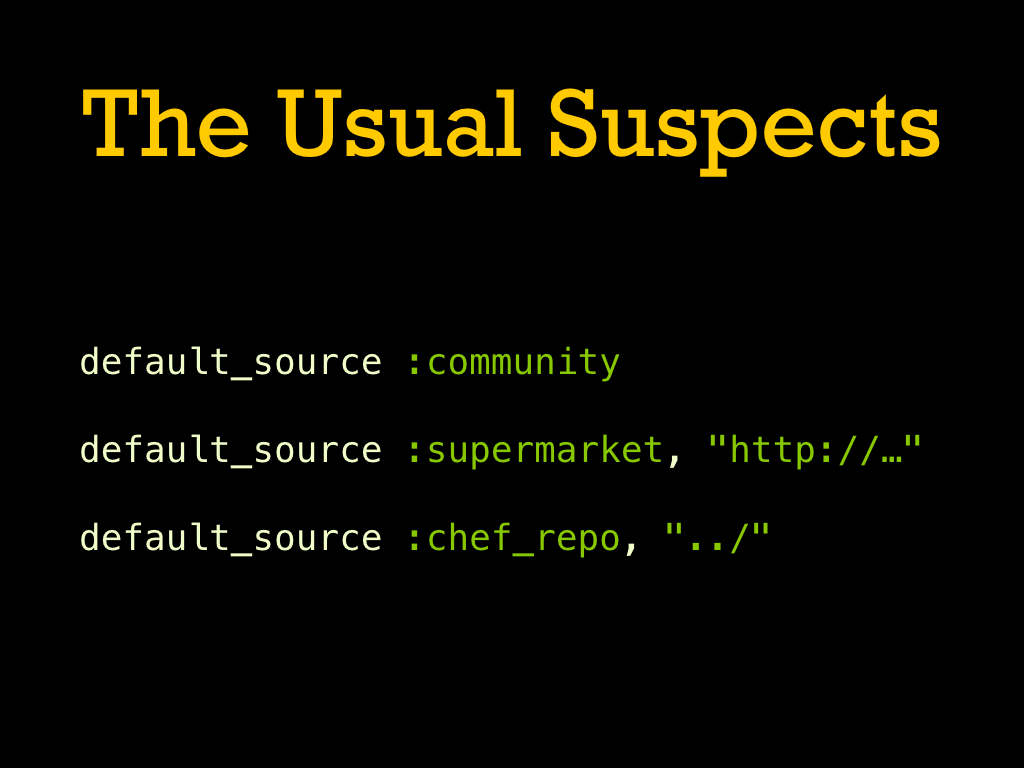
While the default_source lines specify the fallbacks for where to find cookbooks, it can also be overridden on a per-cookbook basis. This can also include version overrides like in an environment. Sources supported include path for things in the same repo or git/github to pull directly from a git branch or tag. |
|
|
The most common default source is to use https://supermarket.chef.io/, but we can also pull in from a private Supermarket or monorepo-style folder of cookbooks. |
|
|
If you have a cookbook that is present in multiple default sources, you will have to resolve which source is preferred. This ensures there is never confusion about where a cookbook is coming from. |
|
|
Policies can also include node attributes, like a role or environment. Unlike those, these are set using the syntax from cookbook attributes files, which makes setting complex nested values a little less verbose. |
|
|
That covers the basic syntax and data for what goes in a Policyfile, now let’s look at the main commands. As mentioned before, the first command you’ll usually encounter is |
|
|
|
|
|
And finally we have |
|
|
By default all policy commands will look for a file named “Policyfile.rb” in the current directory. This makes sense for policies driven by a top-level role cookbook, but in a flatter, central-repository-driven we will usually want a folder with each policy as its own file. Each command will accept an optional argument to specify a path to the policy source. In a repo-centric structure we would generally put these under policies/ to match cookbooks/ and roles/. |
|
|
To pull everything together, a simple example of working with a policy. First we create the policy code and compile it (we’ll just assume we got it right on the first try). Then we deploy the the policy out to stage 1, do something to verify that we are happy with the stage, and then roll it out to stage 2. Later on we have edited some cookbooks and want to pushed them out so we run chef update to recompile the policy, and then use chef push to update each group in sequence like before. |
|
|
Unfortunately it isn’t all roses and unicorns. The Policyfile system is evolving rapidly but there are some issues to know about. |
|
|
The first issue is fact that all users in a policy-based system share a release pipeline for each specific policy. |
|
|
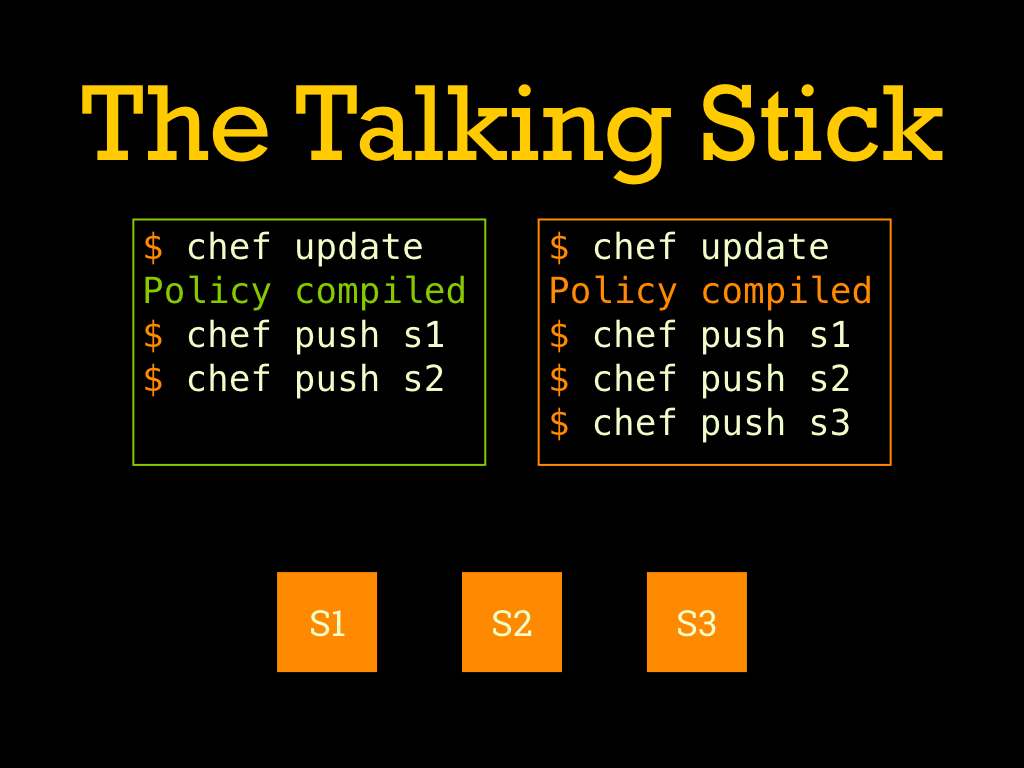
So by way of an example, let’s look at a case with two people trying to push an update to a cluster with three stages. |
|
|
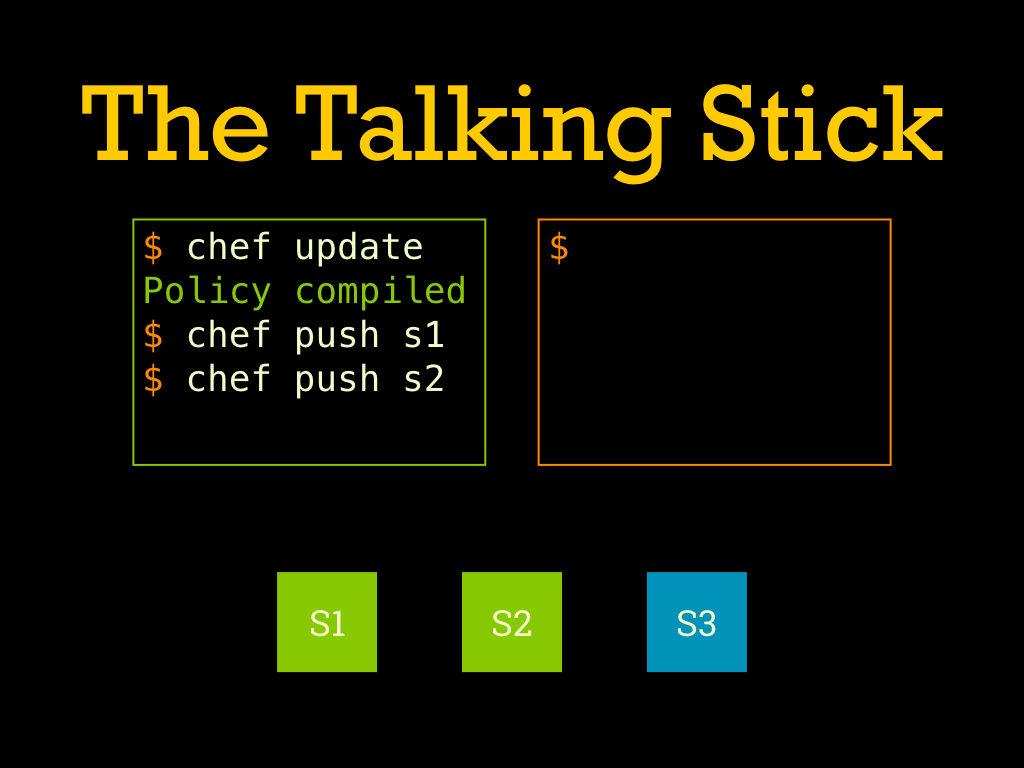
First the green user makes some changes, re-compiles their policy, and pushes the compiled policy to stage one. |
|
|
They do whatever verifications are needed (not pictured), and then proceed to push the compiled policy to stage two. Then let’s say they get bored and go out to lunch. |
|
|
The orange user gets back from lunch early, compiles their own modified policy, and rolls it out to all three stages (again, there would be some verification/burn in between stages but that isn’t the point). |
|
|
Then the green user gets back and finishes their deploy. In the end we have an inconsistent cluster. Stages one and two are running the orange policy but stage three has the green policy. |
|
|
So in short, be aware of when a deploy is happening. If you are deploying on a cluster that you own, this is somewhat easier. If deploying on client clusters, double check with their team(s). |
|
|
A place this single pipeline issue comes into sharp focus is when dealing with a node that runs cookbooks managed by multiple teams. This may require more careful handling of who owns which pieces of the system, what the owner is responsible for, and how teams notify each other of changes. |
|
|
The next major stumbling block is usually around environment-level attributes. Policy attributes map nicely to a replacement for role attributes, but as policy groups aren’t a first-class object themselves there is no direct replacement for environment attributes. Fortunately there are a few patterns that can help. |
|
|
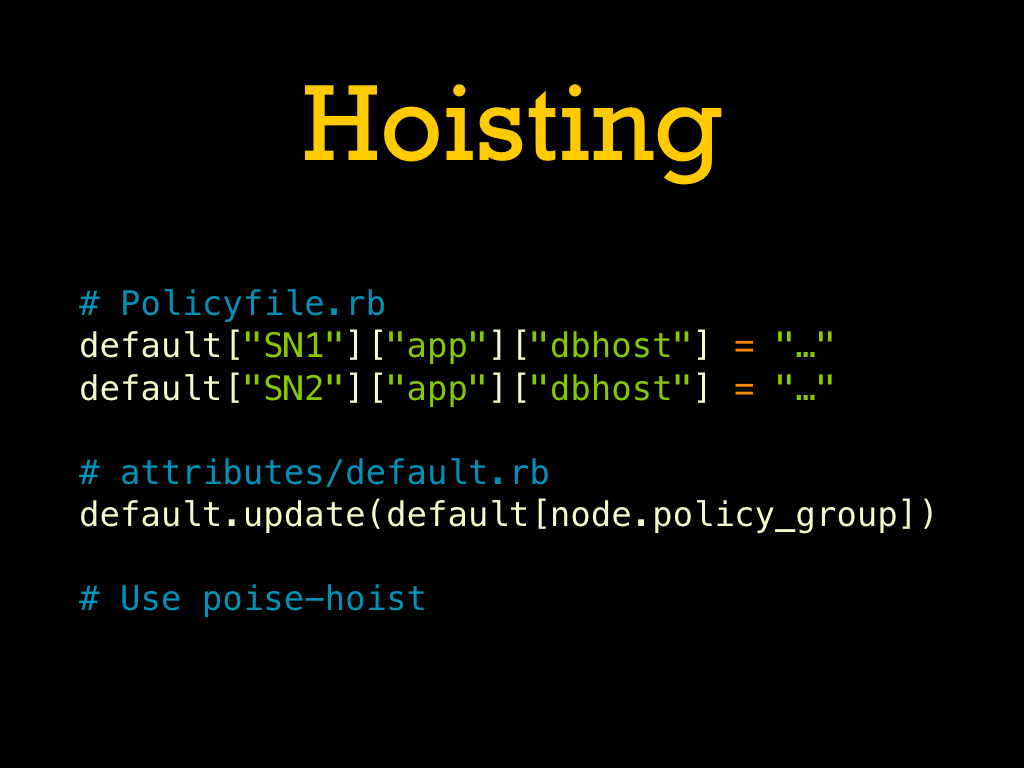
The simplest is to use the group name as a top-level key in the attribute name for things you know will vary by group. You can access the name of the current node’s policy group via |
|
|
For situations where you need to use cookbooks not explicitly designed for this, you can use a hoisting pattern to copy the attribute data out of the group-specific subtree and overlay it on the rest of the attributes. This is often the most robust solution, but the code to implement can be tricky. Fortunately there is a reusable helper you can depend on: poise-hoist. |
|
|
And finally you can skip policy attributes altogether and store environment-level values in a data bag item. This can help with situations where you want attribute data to live outside of the life cycle of the policy itself. |
|
|
You can’t use roles in the run lists of a Policyfile. The biggest case this impacts is having a “base” role applied to all nodes. You can support most of this use case using a shared base Policyfile that is included in all the others. This allows following same snapshot-based workflow while still having some shared data. |
|
|
A downside compared to a Berkshelf-based workflow is that single cookbooks can’t be upgraded without fully re-compiling the policy. Support is planned for the future, but for now take care to diff your compiled policy before pushing to ensure you aren’t releasing something unexpected. |
|
|
ChefDK in general and the Policyfile tools in specific are evolving rapidly. Not everything out there has support for the new workflows but it will probably be added soon. If you run into an unsupported corner of the ecosystem, you can always ask me. |
|
|
So to summarize, some of the major things to look out for are pipeline stomping, data management, and possibly wonky integrations. |
|
|
With our new tools firmly in hand, let’s zoom out to a big-picture look at workflows. |
|
|
A quick version of a traditional Chef cookbook release process. First we updated the cookbook version in metadata.rb, and make sure to follow SemVer. Then we make a git tag, maybe use Stove to push to a Supermarket site, and |
|
|
Usually a release process like this is coupled with SemVer so that we can use that semantic information to structure how new releases flow out to different environments and users. It allows using the pessimistic range operator in environments and dependencies, leaving the version solver in Chef Server and Berkshelf to work out the details. Plus the internet told me SemVer is awesome so clearly I want it! |
|
|
But it isn’t all positive. Tracking which changes are compatible with which other changes presents some cognitive load during development. Additionally when running a release process you often need to release multiple cookbooks in the right order. On top of that, Chef’s version solver is very limited and only supports three component |
|
|
That’s a lot of work. |
|
|
So we want a lighter weight solution. Enter YoloVer: a workflow based around snapshots of a whole run list instead of multiple discrete projects with their own release processes. As you might imagine, this workflow is based around policies and Policyfiles. Using all the tools we just learned, we can manage cookbook deployments with a granularity of whole-repository snapshots. This means we don’t need the overhead of a per-cookbook release system but still retain control over rollouts. |
|
|
So let’s look at an example git repository for a hypothetical monitoring team. We have a folder of local cookbooks specific to the team, and a folder of policies for each type of server we are going to maintain. |
|
|
For the “db” policy we have all the things we saw before. We set the name, as always. Then we set two default sources. Remember these have to be non-overlapping, but it means everything in the cookbooks/ folder will be picked up automatically when needed. We also set one cookbook as coming from a specific git repository. When we take the snapshot, we’ll capture whatever is in the master branch of that repository and use it until we recompile. Finally we set our run list, using cookbooks from all three sources. |
|
|
Having a production workflow is all well and good, but development starts on a workstation somewhere and generally we want to try things locally first. |
|
|
For running our policy locally we’re going to use Test Kitchen with the |
|
|
Let’s start with a basic Test Kitchen config. The is named |
|
|
One of the core concepts of Test Kitchen is the instance matrix. An instance is the combination of a platform and a suite, using the names of each to form the name of the instance. Notably periods in the platform (or suite) name get removed, so be aware of that. |
|
|
To makeTest Kitchen understand policies internally we need to configure the |
|
|
For testing named run lists, we can add a per-suite configuration value. Make sure to nest the |
|
|
Similarly we can use multiple suites to test different policies. This can be combined with the |
|
|
With our trusty |
|
|
Putting it all together we get this Test Kitchen config. We haven’t set up any actual tests yet, but this will let us run the policy in a VM and see if it converges cleanly. |
|
|
Switching to Policyfiles usually means rewriting some amount of roles, environments, and the cookbook equivalents of each to the Policyfile structure. Let’s examine each of those. |
|
|
A pretty simple role for deploying some kind of application. We’re pulling in some kind of base recipe, an application recipe, and set a node attribute for the application’s port. |
|
|
Or to look at it in the form of a role cookbook. The same effective role just in cookbook metadata, attributes, and recipes. You can see the same role data, the recipes are pulled in via include_recipe and the application port is set in the attributes file. |
|
|
Converting this to a Policyfile is fairly straightforward. We have the same run list as with the other forms, and notably the attributes are exactly the same as in the role cookbook making the conversion even easier. |
|
|
Moving on to an environment; here we have a version constraint to lock the postgresql cookbook and an attribute to set Postgres’ data directory. |
|
|
Converting this to a cookbook is a bit less clear. This is following my specific version of the environment cookbook pattern, but yours may look slightly different. We pull in all our role cookbooks, in addition to the version constraint on the postgresql cookbook. Our environment attributes become cookbook attributes, and each role maps to a single recipe. |
|
|
Converting to a Policyfile is similarly dicey. Environments map to policy groups, but this means that it can be difficult to include cross-policy constraints. This is the most direct conversion, starting from the role policy but adding the cookbook constraint and attribute. This works as a kind-of one off but will only apply to the one “role” and we would have to update the policy as we move things through the pipeline if we want different versions of postgresql in different policy groups. |
|
|
A more useful translation is often to use a snippet of Policyfile code that can be shared between the multiple policies. This handles some of the possible use cases, but remember to mesh this on top of the single release pipeline structure. |
|
|
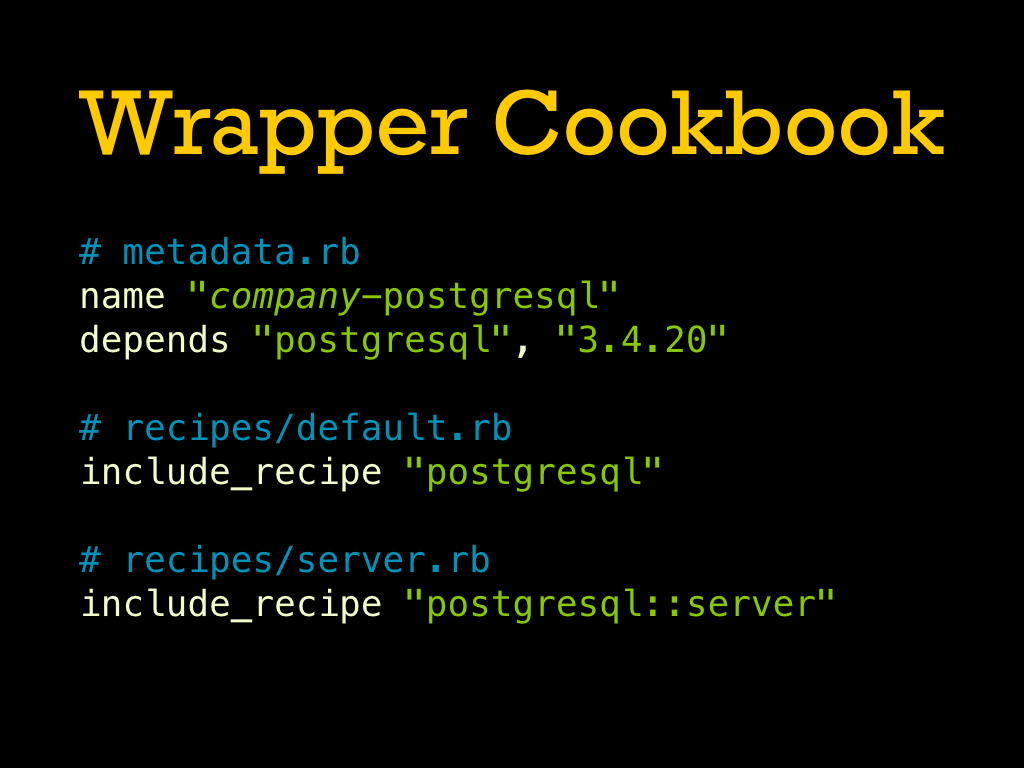
Another option for long-term version restrictions on community cookbooks is to put a stubby wrapper in the policy repo’s cookbooks. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}